¿Qué es la Deduplicación?

Un dispositivo de almacenamiento, como un storage, puede almacenar muchas copias de un mismo archivo. La deduplicación de archivos es otra tecnología más para la reducción de espacio de almacenamiento en las soluciones de protección de datos cuyo fin es eliminar archivos redundantes guardando solamente una instancia del archivo. Con esta técnica, el espacio en disco puede ser reducido drásticamente, lo cual se traduce en ahorro de tiempo y dinero ya que no solo es menos la cantidad que se debe almacenar, también es menor la cantidad de datos que viajan por la red.
A diferencia de la compresión de archivos (hablamos de compresión sin pérdidas, no de la compresión con pérdidas que se aplica a los archivos de audio o video, los cuales al ser descomprimidos ya no son un duplicado del original), que manipulan el archivo mismo para que pese menos de lo que originalmente pesa, la deduplicación encuentra bloques duplicados y/o repetidos de información y guarda solamente una copia de dicho bloque.
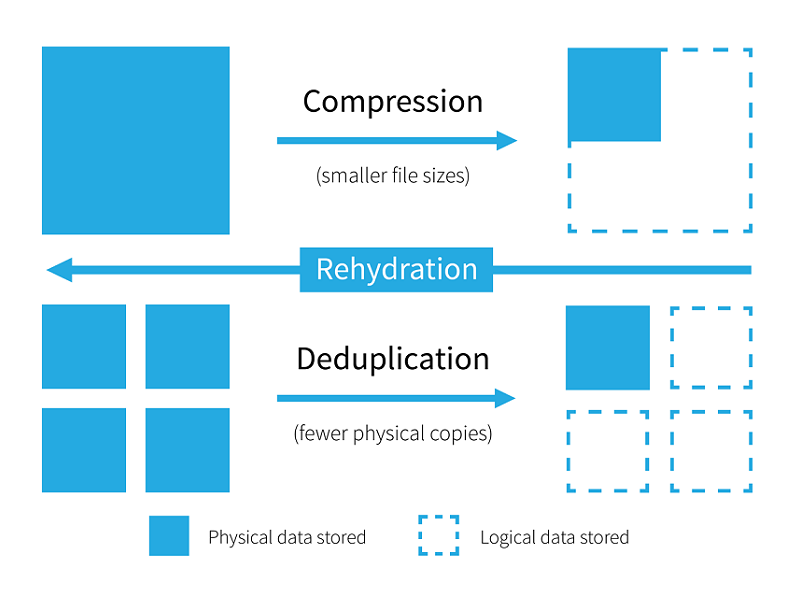
¿Suenan un poco parecidos, verdad? Es que ambos conceptos son un mecanismo para reducir la cantidad de almacenamiento requerido para sus datos. Sin embargo, la diferencia clave es el alcance. La mayoría de los sistemas de compresión funcionan con un archivo, un conjunto de archivos o posiblemente una cinta en una instancia determinada. La mayoría de los sistemas de deduplicación funcionan en un entorno de almacenamiento completo durante un período prolongado de tiempo.
Los sistemas de deduplicación se implementan de muchas maneras diferentes, pero los conceptos básicos son los mismos. Un sistema de deduplicación revisa los bloques de datos en su entorno. Para cada bloque de datos, calcula un valor hash. ¿Qué es un valor hash?
Un valor hash es solo un número grande. Debido a la forma en que se calcula el hash, ese número (valor de hash) debe ser único para cada bloque único de datos. El sistema de deduplicación luego busca en su tabla hash para ver si ha visto o no este valor anteriormente. Si se encuentra el valor, el bloque de datos se elimina y se reemplaza por un puntero al bloque de datos visto anteriormente. Si no se encuentra el valor hash, el bloque de datos se almacena y el valor hash se agrega a la tabla hash. El archivo en sí mismo ahora es solo una cadena de valores hash que se pueden reconstruir buscando los bloques a los que se refieren los valores hash. ¿Sencillo?
Hay tantas implementaciones diferentes de sistemas de deduplicación como vendedores de sistemas de deduplicación.
¿Qué tamaños de bloques se usan para el cálculo del valor hash? ¿Se fusionaron los bloques para crear bloques más grandes? ¿Qué algoritmo hash se usa? ¿Se utilizan múltiples algoritmos hash para evitar colisiones de valores hash? (Una colisión de hash es cuando dos bloques de datos diferentes pueden dar como resultado el mismo valor de hash. Dependiendo del algoritmo de hash, es improbable pero existe una posibilidad matemática). ¿Cómo se indexa la tabla de hash? Estos aspectos de implementación afectarán el rendimiento del sistema y la cantidad de deduplicación (compresión) observada.
Entonces, ¿cuánta deduplicación puedo esperar? Pues el patrón de los datos y la implementación del sistema de deduplicación determinarán la relación de deduplicación. Dado que la deduplicación funciona almacenando solo un bloque de datos una vez, incluso si se ven muchas veces, las aplicaciones de copia de seguridad y archivo tienden a ver las mejores relaciones de deduplicación. La primera vez que realice una copia de seguridad de su entorno en un sistema de deduplicación, la relación de deduplicación será pequeña. Con el tiempo, a medida que continúe realizando copias de seguridad o archivando su entorno, la relación debería mejorar a medida que se vean los mismos archivos repetidamente. Se ha visto tasas de deduplicación oscilar entre 4:1 y 20:1. Algunos proveedores indican que pueden deduplicar a una razón de hasta 200:1, pero eso es con conjuntos de datos muy específicos. Ya una razón de 4:1 representa el doble del ahorro de almacenamiento en comparación con la compresión simple.
Entonces, si tenemos deduplicación, ¿ya no necesitamos compresión? No exactamente. Nuevamente, dependiendo de la implementació, los bloques de datos almacenados se pueden comprimir para ahorrar aún más espacio. Por lo tanto, emplear compresión y deduplicación es lo mejor de ambos mundos.
Además de la reducción del espacio de almacenamiento, hay otro gran beneficio para la deduplicación cuando se están copiando los datos a otra ubicación. La mayoría de los sistemas de deduplicación que tienen una función de replicación remota solo enviarán nuevos bloques de datos en lugar de un archivo o sistema completo. Esto puede reducir drásticamente los requisitos de ancho de banda.
Finalmente, para entornos seguros, los bloques de datos se pueden cifrar. El cifrado generalmente puede disparar la carga en el procesador. En los sistemas de deduplicación solo estamos encriptando bloques que no han sido almacenados previamente, lo que ahorra en procesamiento (menos overhead).
Related Entradas
VRX de Vicarius: La solución perfecta para la gestión de vulnerabilidades
Actualmente, las ciberamenazas a las que están expuestas las empresas no solo son cada vez…
Dante: Aprovecha tu infraestructura TI para transmitir audio digital de alta calidad
Si tu empresa necesita actualizar su sistema de sonido o instalar uno nuevo, una buena…
De la complejidad a la simplicidad: La magia de Cisco Meraki
.Si tu empresa actualmente utiliza múltiples plataformas para administrar sus redes, es probable que hayas…